

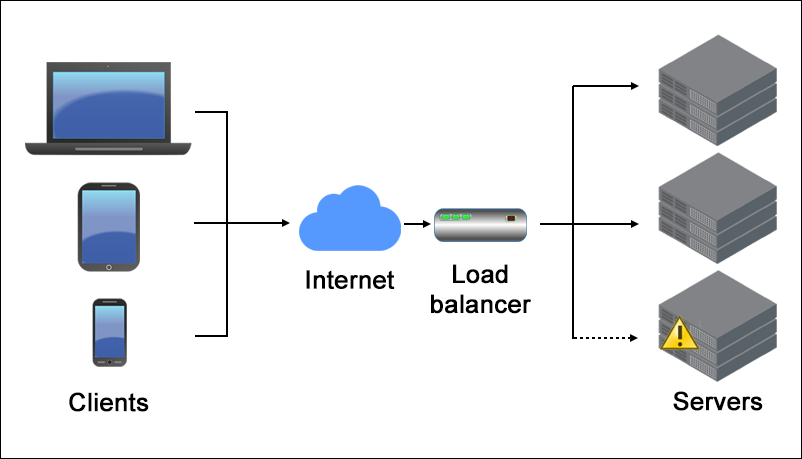
Load balancing is a critical component of any high-traffic website or web application. It helps distribute incoming requests across multiple servers to optimize resource utilization, maximize throughput, minimize response time, and avoid overloading any single resource. This article will provide an overview of common load balancing algorithms and techniques used for web traffic.
Load Balancing Goals
The main goals of load balancing web traffic include:
- Spreading requests evenly across available resources
- Preventing any single component from becoming a single point of failure
- Improving application performance and availability
- Scaling resources to meet changing demand
- Ensuring high throughput
- Decreasing response times for end users
Effective load balancing maximizes speed and capacity utilization while ensuring reliability and redundancy.
Load Balancing Algorithms
There are several common algorithms used to efficiently distribute incoming requests among multiple servers or endpoints.
Round Robin
Round robin load balancing rotates requests evenly between servers listed in a pool. Using this algorithm, the first request is sent to the first server, second request to the next server, and so on, circling back around the pool as needed. This method provides basic load distribution but has limitations such as not accounting for individual server load.
Weighted Round Robin
Weighted round robin builds on standard round robin by accounting for heterogeneous server configurations. Servers with more capacity are “weighted” to receive more requests than others. Server weights are predefined based on specifications so that higher-powered servers get a proportional amount of requests.
Least Connections
The least connections method routes traffic to the server with the fewest active connections at the time of the request. This approach requires load balancers to track open connections on every server in real-time to calculate which one has the lightest load and route requests accordingly.
Least Response Time
With the least response time algorithm, servers with the fastest response times get a greater share of incoming requests. Response times for each server are continuously measured and requests are directed to the server currently offering the fastest speeds. This method requires constant monitoring but provides low latency.
IP Hash
IP hash load balancing uses a hash function to distribute requests based on the client’s IP address. Requests from a particular IP get sent to the same server every time rather than being distributed. This approach has the benefit of maintaining session persistence but can result in uneven loads.
Load Balancer Types
There are two main classifications of load balancers:
Layer 4 Load Balancing
Layer 4 load balancers, also known as transport layer balancers, distribute requests based on transport layer information – source and destination IP address, port numbers. They direct traffic without inspecting the actual content of the request. Layer 4 load balancing is fast and simple but limited in features.
Layer 7 Load Balancing
Layer 7 balancers, also known as application layer balancers, distribute requests based on application layer data within the actual message content. This allows for more advanced distribution methods using factors like HTTP headers, cookies, or data within the request or response. Layer 7 balancing provides greater flexibility and intelligence but with the tradeoff of increased latency.
Load Balancer Features
In addition to basic algorithms for traffic distribution, load balancers can incorporate a variety of key features:
Session Persistence
Also known as sticky sessions, this ensures requests from the same client get handled by the same backend server throughout the session. This is useful for applications that rely on server-side session data.
SSL/TLS Termination
Most load balancers provide SSL/TLS termination, decrypting incoming requests before passing to the backend servers. This takes the computational load of encryption/decryption off the web servers.
Web Application Firewalls
WAF functionality provides deep packet inspection, monitoring requests for threats like SQL injection or cross-site scripting before passing traffic to the backend servers. This protects against exploits at the application layer.
Caching
Load balancers can cache common content like images and static HTML pages and serve these directly, reducing trips to the backend servers to improve response times.
Compression
Compressing server responses before sending them to clients reduces bandwidth consumption and speeds up transmission over the network.
Health Checks
Load balancers periodically check backend server health using pings or TCP handshakes. Unhealthy servers not responding to requests are automatically taken out of rotation until restored.
Load Balancing Methods
There are several ways to implement load balancing for distributing web traffic:
Hardware Load Balancers
Dedicated hardware appliances like F5 or Citrix provide high performance load balancing. They offer advanced traffic management features but can be expensive and inflexible.
Software Load Balancers
Load balancer software like HAProxy runs on commodity servers and can be quickly scaled out through cloud infrastructure. This provides flexible and cost-effective layer 4 or layer 7 balancing.
Cloud Load Balancing
Major public cloud providers like AWS, GCP, and Azure offer fully-managed load balancing services. These integrate natively with other cloud resources and autoscaling capabilities.
DNS Load Balancing
Distributing requests through DNS rotates backend IP addresses in DNS responses when queried. This provides basic load distribution without dedicated hardware.
CDN Load Balancing
Content delivery networks like Akamai and Cloudflare provide global load balancing by routing traffic intelligently across worldwide edge server locations.
Load Balancer Architectures
There are two primary ways to architect load balancers:
Single Load Balancer
Having one dedicated hardware or software balancer sits between the internet and backend servers. This single unit distributes all traffic across the servers in one or more pools. Using a single device simplifies management but provides no redundancy if the load balancer goes down.
Multiple Load Balancers
Implementing multiple load balancers provides redundancy and eliminates single points of failure. This can be done through active-active or active-passive modes. In active-active, traffic is actively handled by multiple devices simultaneously. In active-passive, secondary balancers sit idle until needed to failover from the primary.
Load Balancer Deployment Models
Load balancers fit within the overall IT infrastructure in several ways:
Two-Tier Load Balancing
A two-tier model has a frontend load balancer distributing requests between backend application servers. This is a simple but limited approach.
Three-Tier Load Balancing
In three-tier models, one balancer sits in front of application servers and another in front of database servers. The frontend balancer distributes application traffic while the backend handles database load distribution.
Full Proxy vs Reverse Proxy
In full proxy models, clients connect directly to the load balancer which then passes requests to the backend servers. In reverse proxy, clients first connect to web servers which then pass requests on to balancers for distribution.
On-Premise vs Cloud
Load balancers can be deployed as physical or virtual appliances in enterprise data centers or leverage managed cloud load balancing services offered by public providers.
Load Balancer Concepts and Strategies
There are some key concepts and strategies to consider when implementing load balancing:
Equal vs Proportional Balancing
Equal load balancing distributes requests equally whereas proportional balancing accounts for disparate server specs and distributes loads proportionally.
Stateless vs Stateful Distributions
Stateless distributions decide request routing independently on each request while stateful methods track past requests and server-side sessions to route related requests accordingly.
Layer 4 vs Layer 7 Balancing
Layer 4 balancing routes requests based on IP and transport layer data while Layer 7 examines the actual application layer content to make smarter routing decisions.
SSL/TLS Offloading
Offloading resource-heavy SSL encryption processes from backend servers to dedicated listeners on the load balancers greatly improves performance.
Sticky Sessions
Sticky sessions ensure a user’s session stays on the same server. This preserves application state and session data on the backend.
Health Monitoring
Checking server health and performance metrics to take unhealthy servers out of rotation is crucial for reliability. Load balancers must incorporate robust health checks.
CDNs and Geo balancing
Using CDNs and geo-routing to localize traffic across worldwide regions greatly reduces latency for globally distributed users.
Load Balancing for High Availability
Proper load balancing is crucial for high availability and reliability in large-scale web applications and services. Key high availability strategies include:
Eliminating Single Points of Failure
Having redundant components like multiple balancers avoids downtime if one fails.
Active-Active and Active-Passive Redundancy
Active-active and active-passive balancer configurations provide failover capabilities to handle traffic if the primary balancer goes down.
Health Checks and Failover Triggering
Automated health checks that trigger automatic failover to standby components minimize downtime.
Session Replication
Replicating session data across backend servers prevents loss of state and connectivity when shifting users between endpoints.
Geographic Redundancy
Distributing redundant infrastructure across geographic regions helps withstand localized failures.
Load Balancing in the Cloud
Cloud load balancing is widely deployed using cloud provider managed services like AWS Elastic Load Balancing, Azure Load Balancer, and Google Cloud Load Balancing. Key considerations for cloud load balancing include:
Autoscaling Groups
Cloud load balancers integrate tightly with autoscaling groups to dynamically scale backend resources up and down based on demand.
Cloud Monitoring and Metrics
Cloud services provide detailed metrics on balancer and backend server performance to fine-tune configurations.
Globally Distributed Load Balancers
Global cloud load balancers distribute traffic across regions while localized balancers route to resources within the same region.
Elastic IP Addresses
Cloud load balancers map to elastic IPs that dynamically route to the active balancing resources. Backup balancers can quickly assume roles.
Security Group Configuration
Security groups tightly control what traffic can reach load balancers and backend instance pools.
Load Balancer Challenges
There are some key challenges and limitations to consider with traditional load balancing approaches:
Session Persistence Difficulties
Sticky sessions that route a user’s entire session to the same backend can be resource intensive and complex to implement.
Scaling Inefficiencies
Hardware balancers don’t autoscale, resulting in overprovisioning. Cloud balancers alone don’t efficiently scale backend instances.
Feature Disparities
Hardware solutions excel at throughput but lack features. Software and cloud balancers provide features but are less performant.
Vendor Lock-in
Many load balancers use proprietary software and interfaces, resulting in a lack of portability.
Single Point of Failure
The load balancer itself can become a single point of failure. Multi-balancer designs help address this.
Global Server Load Balancing
Global server load balancing (GSLB) routes traffic across resources distributed worldwide. Key aspects include:
Intelligent Routing Based on Geography
GSLBs analyze the geographic location of each request and direct it to the nearest frontend with the lowest latency.
Load Balancing Between Regions
Regional frontend load balancers distribute requests to backends within the region. GSLBs route across regions.
Health Checking Across Global Infrastructure
GSLBs monitor worldwide infrastructure health in real-time to determine optimal regional routing.
Failover Across Regions
If an entire region becomes unavailable, GSLBs transparently failover and direct all traffic to alternate regions.
DNS-based Request Routing
GSLBs use DNS to return different IP addresses based on location to route end users.
Coping With Global Traffic Spikes
GSLBs can rapidly scale up capacity by bringing additional regions online to handle large traffic spikes.
Load Balancer Best Practices
Some key best practices for implementing load balancing include:
- Use health checks to monitor backend servers and take unhealthy ones out of rotation.
- Ensure load balancers themselves have redundancy to avoid single points of failure.
- Align load balancer algorithms and configurations with application requirements. There is no one-size-fits-all approach.
- Use cloud integration for dynamism and automation in provisioning load balancers and backends.
- Take advantage of CDNs for geographically localizing traffic and failover across regions.
- Analyze detailed metrics across all tiers and components to identify bottlenecks.
- Scale load balancers along with adding backend server capacity to maintain optimal ratios.
The Future of Load Balancing
Load balancing will continue evolving alongside microservices, containers, service meshes and other emerging technologies. Future developments may include:
Integration With Service Mesh Architectures
Service meshes like Istio and Linkerd integrate load balancing capabilities for East-West traffic between microservices.
Greater Serverless Integration
Managed cloud and serverless platforms will handle more load balancing complexity behind the scenes.
Increased Autoscaling Capabilities
Autoscaling will become smarter about scaling load balancers, not just backend servers, to maintain ideal ratios.
Better Cloud and Container Integration
Load balancing services will become more optimized for automated container orchestration and provisioning.
More Granular Load Distribution
Load balancing will happen at the individual request or message level vs. connection-level for greater efficiency.
Improved Algorithms and Predictive Analytics
Smarter algorithms will combine real-time metrics with predictive models to optimize traffic distribution.
In conclusion, load balancing is a fundamental component of distributed systems and will continue evolving as architectures shift to the cloud, containers and microservices. Following core load balancing principles and best practices will ensure high-traffic applications remain fast, reliable and scalable even as traffic grows.